主页 > 下载imtoken钱包官网苹果版 > 基于云平台的区块链组网方案及数据共享存储机制
基于云平台的区块链组网方案及数据共享存储机制
基于云平台的区块链组网方案及电子论文数据共享存储机制
时间:2019年10月28日分类:电子论文点击次数:
摘要:为解决区块链上数据存储共享过程中交易确认效率低、存储空间利用率低的问题,提出一种基于云平台部署的区块链组网方案及其适配数据共享存储解决方案。首先,通过对传统的全连接区块链网络进行分解重构,形成基于子网的非全连接网络。
摘要:为了解决数据在区块链上的存储和共享过程为了解决交易确认效率低、存储空间利用率低的问题,本文提出了一种基于云平台部署的区块链组网方案,适应它的数据共享存储方案。首先,通过对传统的全连接区块链组网进行分解重构,形成基于子网的非全连接组网方案,将交易确认的范围限制在有限的节点内。
其次,通过将数据划分为交易数据敏感状态数据-非敏感状态数据三个层次进行管理,节点只保存与状态转移相关的交易数据,保证状态数据不可篡改。在云平台上实现不同级别的共享存储,以最大化存储空间。实验结果表明,该方案可以为区块链中可信数据的存储和共享提供新思路。
关键词:云计算;区块链;数据共享

0 简介
近年来,区块链成为社会热点。它集点对点传输、分布式数据存储、共识机制、加密算法等技术于一体,具有不可篡改、可追溯、去中心化等特性,这些特性使区块链成为存储和共享可信数据的理想选择。
目前对区块链数据存储和共享机制的研究主要面临两个问题:1)交易确认效率。由于区块链的每一次状态更新都需要全网多数节点确认形成共识,并向各节点广播同步账本全网,参与网络的节点越多,运行速度越慢。交易确认速度。 2)存储空间使用问题。因为区块链是不可变的、不可删除的,所以存储在区块链上的数据只会随着时间的推移而增长,从长远来看会消耗大量的存储空间。
通过引入云计算的概念,可以在一定程度上改善上述问题。区块链与云计算的结合称为区块链即服务(BlockchainasaService,BaaS)[1],可以有效降低区块链部署成本,利用云计算快速搭建区块链服务。 2015年11月,微软在Azure[2]云平台上提供BaaS服务,并于2016年8月正式向公众开放。开发者可以以最简单、最高效的方式创建区块链环境。
IBM[3] 还于 2016 年 2 月宣布推出区块链服务平台,以帮助开发人员在 IBM 云上创建、部署、运行和监控区块链应用程序。国内阿里云[4]、腾讯云[5]也相继提供了BaaS服务。本文提出了一种基于云平台部署的区块链组网方案和与之相适应的数据共享存储方案。它主要具有三个特点: 1)介绍了Confirmation的思想仅限于有限数量的节点。 2)数据按照敏感程度分层存储,在保持不变性的前提下提高存储空间的利用率。 3)专为云计算环境下的部署而设计,让用户可以通过云平台快速搭建区块链服务,降低部署成本。
1 相关工作
关于区块链数据的存储和共享机制,国内外已有很多相关研究。这些研究讨论了如何在不同的应用场景中使用区块链。将可信数据存储在区块链上,一方面充分利用区块链的不可变特性来保证数据的安全性,另一方面需要将存储在链上的数据共享给在保证隐私的前提下拥有访问权限的用户。文献[6]研究了医疗数据的共享模型,采用改进的DPOS机制实现节点间的共识,最终通过自定义的一套分层存储结构将所有数据Merkle根锚定到比特币区块链上,实现真正的不可变和不可抵赖.
文献[7]研究了基于联盟区块链的智能电网数据的存储和共享。本文以数据采集基站作为区块链的节点,对无线传感器网络的数据进行采集、审计和分析。存储,然后在网络节点之间共享。数据的“记账权”需要通过 POW 机制,通过预选节点之间的竞争获得。文献[8]研究了人文社科的数据共享模型,以HyperledgerFabric区块链框架作为联盟链的基础,改进了区块的数据存储方式,用关系型数据库的存储方式替代了传统超级账本的key价值转价值的数据存储方式,可以提高链上数据的查询处理能力,提高人文社科数据共享平台的溯源和追踪效率。

文献[9]设计了BBDS系统,为存储在云平台的共享医疗数据提供数据源、审计和控制,主要解决了去信任环境下的医疗数据共享问题。该设计采用智能合约和访问控制机制来有效跟踪数据的行为,并在检测到违反数据权限时撤销对违规实体的访问。文献[10]建立了基于HACCP(Hazard Analysis and Critical Control Points)、区块链和物联网的食品供应链实时追溯系统,为所有供应链成员提供了一个开放的信息平台。
供应链中的数据通过 BigchainDB 存储。 BigchainDB[11] 是 TrentMcConaghy 等人提出的高度可扩展的区块链数据存储架构。它继承了分布式数据库的特点:吞吐量和容量可以根据节点数量线性扩展,提供功能齐全的NoSQL查询语言,查询效率高,权限控制机制完善。
文献[12]提出了一种基于云计算的物流区块链模型。通过结合区块链共识机制和Hadoop分布式存储技术,设计了CloudPBFT算法。与经典的 PBFT 算法相比,吞吐量和网络延迟都有所提高。以上相关工作在不同程度上提高了交易确认效率和存储空间利用率,但也存在一定的局限性。本文的方案从四个方面与上述研究结果进行了比较和评价。
本文方案之所以在交易确认效率和存储空间利用率上更胜一筹的原因在于:1)采用非全连接组网方案,状态更新不需要获取大部分全网节点可以通过确认达成共识,从而减少网络请求量。 2)采用基于云平台的数据存储机制。一方面,节点只需要保留少量可以保证不变性的交易数据。另一方面,可共享的状态数据被进一步压缩和存储,以达到更高的空间利用率。
2 基于云计算的区块链网络设计
2.1 目前主流的区块链组网方案
在主流的区块链架构中,设计者追求模型的泛化能力,试图在软件级的框架中提出一种通用的方法来解决分布式网络中节点间公共状态的同步和同步。更新问题,这种方法通常被称为共识算法。目前主流的共识算法包括以数字货币为代表的公链中使用的POW[13]、POS[14]和DPOS[15]算法,以及PBFT[16]、RAFT[17]、Paxos[18]算法等开。
共识算法的研究通常是理论性的,假设任何一个节点都是全连通的,并且是必须连通的,此外,它还假设节点之间的信息交互是完全随机的。在全连接模型中,每次状态更新都需要得到所有成员的确认。在通常的客户端-服务器模型中,如果一个节点需要更新 N 个状态,它只需要向服务器发送 N 个网络请求;但是在全连接网络中,对应的节点每更新一个状态,就需要将其A网络请求广播给所有其他节点,网络请求总量为N×(M-1),其中M为分布式网络中的节点总数。
当节点总数增加时,必然会影响交易确认的效率。基于此考虑,本文将研究现实世界中不同实体之间的真实连接关系,尝试建立新的结构化模型,在网络拓扑层面实现共识算法。
2.2 一种非全连接的区块链网络构想
2.2.1 结构化模型
所有类似于自然或人类社会行为的算法模型,无论自然或人类社会中的个体之间,很少有个体会与所有其他个体相互作用,即几乎不存在全连接模型通常,每个个体只与几个个体有密切接触,也就是说,实际模型是由若干个稀疏图组成的集合。
在实际的网络拓扑中,图之间没有联系,也没有数据交互。因此,不需要在不同的图之间存储其他图的内部数据,这是在网络结构层面达成共识的第一步。在每个图中,节点之间的数据交互关系可以归结为两种基本模型,即单一的主从关系和相互的主从关系。箭头指向的节点称为“父节点”,箭头发送的节点称为“子节点”。在单一的主从关系模型中,每个对账本的“写”请求都只从父节点发出,子节点只负责验证父节点的请求。

当然,账本是否可以合法写入是由父节点和子节点决定的。供应链是典型的以单一主从关系为主的结构,数据基本上是单向流动的。例如,交易只能由供应商发起并由客户确认。在相互主从关系模型中,每个节点都可以随机发起写请求,没有明显的从属关系。微信等即时通讯工具属于典型的相互主从关系模型,通信双方可以随时对账本(聊天记录)进行“追加写入”操作。
严格来说,相互主从关系模型也可以分解为两个独立的单主从关系模型。是否需要进一步细分,可以根据网络规模和节点间交易的关联程度来确定。一般来说,网络规模越大,交易关联度越低,越需要细分。
在人类社会的经济活动中,单一的主从关系模式是主流,即生产关系比较稳定,变化的频率较小。随着节点数量的增加,以相互主从关系模型为基本组成部分的结构,在实际业务中将越来越少。遇到实际问题时,需要分析节点之间的逻辑关系,确定具体的实施方案。主要有两种基本实现方式:1)混合使用两种基本模型进行建模;2)将所有事务分解为单个主从关系,进行最终综合建模。本文将重点研究后一种方案。
2.2.2 模型分解与重构
根据上一节的分析,本文将基于单一的主从关系模型对实体经济活动进行分解,形成一系列更小的结构,这些结构按照一定的顺序重新组合,从而达到理清网络结构,有序交易过程的目的。本文的最终目标是对整个网络的数据流进行分类和处理,数据流的方向用“边”表示,即原始网络中的“单向边”(简称“原始图”)需要重做。整洁。
因此,基于原图重构的新图必须包括原图的所有边(每条双向边需要拆分为2条单向边)。首先将原图的长路径截断,将所有指向同一个节点的边归为同一类,从而形成基本的单层结构,可以称为“原子树”,意思是不再细分树。
一种可行的做法是依次扫描原图,找到所有的父节点(即有几个箭头指向的节点),根据每个父节点对原图进行划分。然后依次找到每个父节点的子节点,最后形成几棵原子树。节点1、2、3是原子树的父节点,子树之间通过“信使节点”连接,即节点2和3。显然,一个可以成为信使节点的节点必须同时与至少一个“in-edge”和“out-edge”相邻。
2.2.3组网方案设计
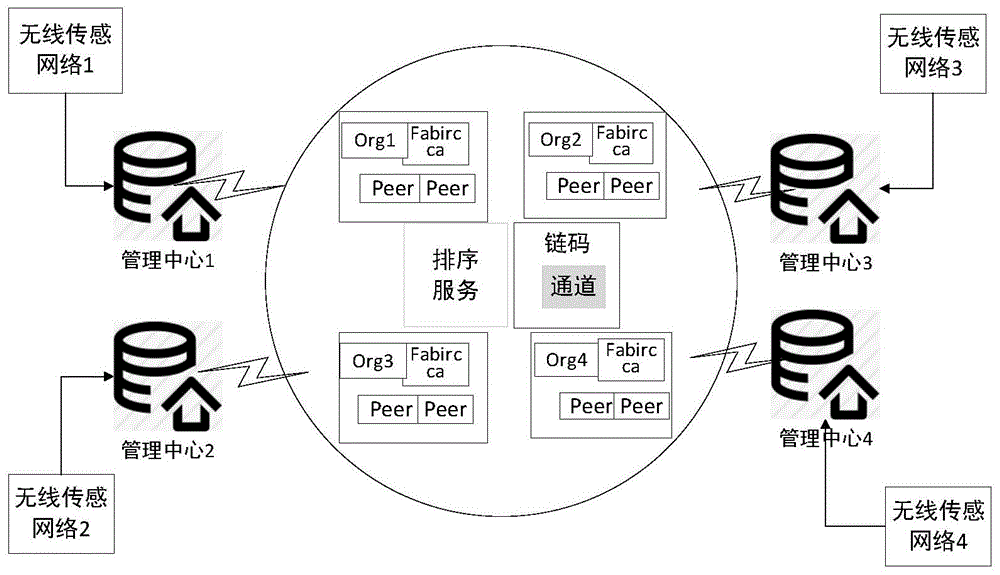
每个原子树中的每个节点都共同维护着树中的数据流,这些数据流之间的相关性比较大。因此,原子树中的所有交互数据都可以写入同一个分布式账本中。原子树中的节点共同组成一个区块链网络,本文称为子链。网络。每个子网需要包括以下基本角色:1)授权和认证节点。即CA,主要使用数字证书机制来管理网络中的成员资格。 2)普通节点。发起交易或通过签名为交易背书。
3)排序节点。收到的合法交易在网络中全局排序并打包成块。 4)完整节点。验证区块并维护整个账本。此外,授权的外部节点或客户端可以访问部分或全部分类帐数据。从上面可以看出,每个新的子网都需要分配全节点和排序节点。在云计算环境下,虚拟机资源的分配非常灵活,可以通过脚本实现自动化部署。因此,该组网解决方案可以在云计算环境中实现最高的运行效率。不过需要注意的是,在非云计算环境下,组网方案还是可行的。
粗箭头表示不同模块之间的信息交互,细箭头表示模块内的信息传递过程。实线表示交互是主要的,虚线表示交互是次要的。
3基于云计算的区块链数据存储机制
3.1 数据存储架构设计

本文数据存储架构的思想来源是基于IBM牵头的具有代表性的联盟链项目HyperledgerFabric [19]项目。在 Fabric 中,账本是一系列有序的、不可变的状态转换记录。状态转移是链码执行(交易)的结果,每笔交易通过增删改操作向账本提交一系列键值对[20]。一系列有序的交易被打包成区块,从而将账本连接成区块链。同时,状态数据库维护账本的当前状态,因此得名世界状态。账本状态数据库实际上存储了曾经出现在交易中的所有键值对的最新值。
调用链码执行交易可以改变状态数据。为了高效地执行链码调用,所有数据的最新值都存储在状态数据库中。从逻辑上讲,状态数据库只是有序事务日志的快照,因此可以随时从事务日志中重新生成。基于这一思路,结合云计算的特点,本文进行了一定的拓展,形成了基于云计算的区块链数据存储机制。这种机制将要存储的数据分成两部分:交易数据和状态数据。
交易数据包含与状态转移相关的关键内容。目的是保证整个网络的秩序保存和不变性。它通过区块链结构存储。块应包含以下字段:1)交易详情。指示相关节点之间实际发生的流量。 2)交易创建者的标识符。指示交易是由哪个节点生成的,即生成器的完整签名。 3)交易的验证者 ID。交易的接收方确认交易详情及其生成者的标识符是合法的,最后签署交易。 4)前一个区块的唯一标识符。表示当前区块数据附加到哪个区块,通常是前一个区块的序列化哈希值。
5)块号。表示当前块为全局块号。 6)当前区块的唯一标识。当前区块的序列化哈希。 7)块类型。指示当前块的类型,例如普通块或创世块。状态数据类似于上面提到的世界状态概念,是整个子网的全局状态。 Fabric 提供了两个选项,LevelDB 或 CouchDB。但是这两个数据库能够支持的查询方式较少,不能很好地满足商业级应用复杂的查询需求。
其实可以认为只要交易数据能够保证账本的不变性,状态数据就可以存储在其他性能更好的数据库中。考虑到在实际应用中,用户对数据加密级别的要求不同,所以状态数据可以分为只有子网成员才能看到的敏感数据和可以对外共享的非敏感数据。
节点A和节点B组成子网1,节点B和节点C组成子网2。其中节点B同时存储两个子网的交易数据。这两个子网都配备了全节点集群,用于在子网中存储敏感数据。这部分数据由子网中的节点共享,而每个子网的非敏感数据可以存储在全网数据共享服务器集群中。本文方案中的状态数据通过部署在云服务器上的HBase数据库进行存储。
Hbase[21] 是一个分布式的、面向列的开源数据库。该技术来自 Chang 撰写的 BigTable [22] 论文,是针对海量非结构化数据的高性能存储解决方案。 HBase支持基于Snappy[23]算法的压缩存储功能,可以最大程度的节省存储空间。同时,由于节点拥有与状态变化记录直接相关的交易数据的所有权,仍能有效防止状态数据被篡改。
3.2 典型过程分析
3.2.1 子网构建过程
Step 1 所有类型的节点在加入网络之前,需要向CA申请相应的证书。 Step 2 节点要创建子网时,首先从CA获取相应成员的证书、IP、权限等,并根据IP向其他节点发起组网请求。 Step 3:组网规则(如所有节点都同意)通过后,发起初始请求的节点生成签名的创世块,并将排序节点和全节点分配给子网。
3.2.2数据存储过程
步骤1中子网内任意节点生成事务/记录的前提是已经向CA提出了相应的申请。证明其身份的证书。步骤2:对于子网中某个节点发起的交易,根据子网中参与交易的成员数量,需要对应的节点对该交易进行签名。例如,如果节点 A 发起一个涉及 A、B 和 C 的交易,那么该交易必须包含 A、B 和 C 的所有签名才能合法。此时,无法进行离线交易。如果交易只涉及A本身,则交易可以离线。行为。
节点A收集步骤3中的所有签名后,将带有序号(表示当前全局事务号)的交易发送给ordering节点,ordering节点通过共识/容错算法返回accept或被拒绝的回应。第四步:如果排序节点接受交易,则对交易进行签名,连同交易内容的哈希一起广播给所有节点,相当于同步向所有节点添加一个新的交易数据。 Step 5 与上一步同时,排序服务器将事务分为敏感数据和非敏感数据两类。敏感数据提交子网全节点服务器存储,非敏感数据提交全网数据共享服务器存储。

3.2.3 数据查询流程
Step 1 节点通过客户端发起查询请求,节点所属节点首先验证客户端的身份和权限。第二步,如果验证通过,则分别向全网数据共享服务器和子网全节点服务器发送查询。步骤3和步骤2中的两类服务分别返回请求的敏感和非敏感数据字段信息。节点服务器将它们组合后,取哈希值对自己存储的交易数据进行验证。 Step 4 节点将数据返回给客户端。
4 实验与分析
4.1 实验数据
本文提出的非全连接网络方案旨在模拟人类社会行为,因此在试验真实世界的数据模型时可以取得最佳效果。供应链是区块链技术的热门应用场景,也是基于单一主从关系的典型结构。在供应链中,数据流动基本上是一种方式,交易由供应商发货并由客户确认。
笔者所在机构在本文基金项目的资助下,在广州多个肉类蔬菜批发市场和农家菜市场对基于区块链的农产品溯源模型进行了一系列探索。一个供应链基础数据模型,至少有3个层次,100个节点,代表上游供应商-运输商-批发商-零售商之间的关系。
在供应链的基本数据模型中,每个上游节点都可以看作子网的父节点,其下游是子节点。可以是父节点。通过非全连接模型,可以将庞大的供应链拆分为子网络,下面将基于模型进行测试和分析。
在上面提到的农产品供应链溯源应用中,数据主要存储在以下5个表中:1)Product.当前节点的主要产品信息,包括产品名称、产地、价格等,这部分数据经过加密存储在子网全节点服务器中。 2)客户。当前节点的客户信息,包括客户姓名、联系电话、身份证号、营业执照等,这部分数据经过加密存储在子网全节点服务器中。 3)供应商。当前节点的供应商信息区块链需不需要服务器,包括供应商名称、联系电话、营业执照、经营范围、地址等,这部分数据经过加密存储在子网全节点服务器中。
4)购买。当前节点的采购记录,包括采购订单号、成交日期、采购明细(包括商品、批次、数量、价格等)、供应商、总价、运输物流订单等。 日期、商品、数量等在不暴露节点身份的前提下属于非敏感数据,因此可以存储在全网数据共享服务器中,其余信息加密存储在全节点服务器中子网的。 5)出售。当前节点的销售记录,包括销售订单号、成交日期、销售明细(包括商品、批次、数量、价格等)、客户、总价、运输物流订单等。 日期、商品、数量等在不暴露节点身份的前提下属于非敏感数据,因此可以存储在全网数据共享服务器中,其余信息加密存储在全节点服务器中子网的。
4.2个实验环境
本文所有应用均部署在云平台上,排序服务器和数据库服务器根据子网的形成动态分配。
4.3个实验结果
为了验证本文提出的方案的可行性,下面对本文使用全连接组网方案和非全连接组网方案进行对比。该方案在不同节点数下的吞吐量,以及本文提出的经典区块链数据存储方案和三级数据共享存储方案的存储空间效率。
4.3.1 吞吐量比较
将供应链基础数据模型中的100个节点进行拆分,分别测试不同数量的节点使用全连接组网方案和非全连接组网方案的吞吐量。全连接组网方案在节点数较少时吞吐量较高,但随着节点数的增加,吞吐量会急剧下降。其他所有节点广播一个网络请求,网络总请求量为N×(M-1),其中M为分布式网络中的节点总数,所以节点数越多,请求时间越长交易确认时间和吞吐量越高,金额越低。
非全连接组网方案将一个大的全连接网络拆分成不同的子网,交易只需要相关方确认即可,不需要所有节点,因此,当节点数量增加时,呈下降趋势它的吞吐量并不明显。在100个节点的情况下,非全连接网络的吞吐量达到全连接网络的8.8倍。
5 个结论
本文优化了在云计算环境中部署区块链的方案,提出了一种新的区块链组网机制,提高了网络的整体吞吐量;同时,通过引入基于云计算的数据共享存储,最大限度地优化了存储空间。后续将继续对本文的理论基础进行深入研究,方向包括:不同数据共享模型应用于区块链数据存储时的存储空间、查询延迟、吞吐量等对比;模型在各种突发情况下(节点下线、恶意节点攻击、分叉等)的抗风险能力。
参考资料:
p>
[1]SAMANIEGOM,DETERSR.BlockchainasaServiceforIoT[C]
[2]Microsoft.AzureBlockchainSolutionArchitecture[EB/OL].[2019-07-15].
[3]IBM.TheIBMBlockchainPlatform[EB/OL].[2019-07-15].
[4]阿里巴巴.阿里巴巴云区块链服务[EB/OL].[2019-07-15].
[5]腾讯。腾讯云区块链服务[EB/OL].[2019-07-15].
[6]薛腾飞,傅群超,王聪,等。基于区块链的医疗数据共享模型研究[J].自动化学报, 2017, 43(9):1555-1562.
[7] 吴振权,梁玉辉区块链需不需要服务器,康嘉文,等。基于联盟区块链的智能电网数据安全存储与共享系统[J].计算机应用, 2017, 37(10):2742-2747.
[8] 顾俊,许昕。 Design and implementation of data sharing model for humanities and social sciences——Taking alliance chain technology as an example [J]. Journal of Information Science, 20 19, 38(4):354-367.
Submission of blockchain networking scheme: Journal of Automation (Monthly) was founded in 1963 by the Chinese Society of Automation, A high-level academic journal co-sponsored by the Institute of Automation, Chinese Academy of Sciences. Publish high-level theoretical and applied scientific research results in the field of automation science and technology.






